Axel Cohen
|
0
|
January 17, 2023


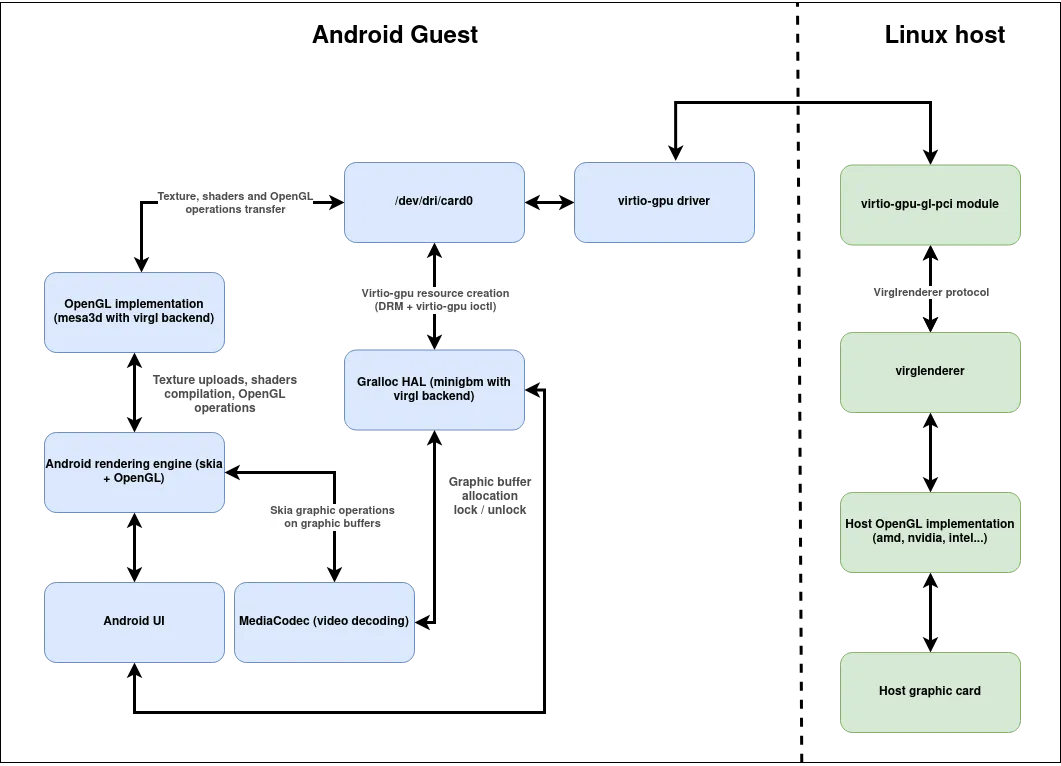
Currently experimenting on a Android 12 guest virtualized with qemu, more specifically with the graphical stack integration. For performance reasons we chose to try the virtio-gpu / virgl solution, which leverages your host graphical hardware rendering capabilities (instead of a using full software solution such as SwiftShader).
Components integrated on the guest:
On the host side we use:
-device virtio-gpu-gl-pci,id=gpu0,xres=1080,yres=1920
-display egl-headless
-vnc 0.0.0.0:0
The result is smooth OpenGL rendering of the Android UI with low CPU usage (interacting through VNC).
Here is a global architecture overview:
Unfortunately, trying to show Big Buck Bunny on Youtube will display something like this:

At first, it seemed easy enough like probably some system property for the colorspace. However, after plenty of tinkering, nothing helped improving that rendering. By looking more in details, we can see that:
First the actual software H264 decoding is handled with libavc, but all we care about is codec2 (Android low level A/V framework), which renders original YUV frames in YV12 format.
And indeed if we try rendering a video with RGB encoding, then everything is displayed correctly. So YUV rendering is the actual issue here !
And then things became more complicated from there and gave us a great reason to get our hands dirty.
The plan was to follow our buffer from it's creation to the final rendering on the host to find out where something went wrong.
First the actualy software H264 decoding is handled with libavc, but all we care about is what happens afterwards in codec2.
High level software video decoding in our current Android graphic stack looks like this:
DRM_IOCTL_VIRTGPU_RESOURCE_CREATE with the total size in bytes of the buffer, and gets a handle referencing itDRM_IOCTL_PRIME_FD_TO_HANDLE and gets a mappable fd (which can also be used to get back the original handle), which is stored in the C2 graphical buffer structureWe then started adding debug code to actually dump the frames at different places. In codec2 (C2SoftAvcDec.cp) right after decoding, it looked like this:
if (ps_decode_op->u4_output_present) {
static int frame_count = 0;
const char path[256] = {0};
sprintf((char*)path, "/data/local/tmp/frames/c2_frame_%d", frame_count);
int fd = open(path, O_RDWR | O_CREAT, 0644);
if (fd < 0) {
ALOGW("failed to open %s", path);
}
int ysize = ps_decode_ip->s_out_buffer.u4_min_out_buf_size[0];
int csize = ps_decode_ip->s_out_buffer.u4_min_out_buf_size[1];
write(fd, ps_decode_ip->s_out_buffer.pu1_bufs[0], ysize);
write(fd, ps_decode_ip->s_out_buffer.pu1_bufs[2], csize);
write(fd, ps_decode_ip->s_out_buffer.pu1_bufs[1], csize);
close(fd);
frame_count++;
finishWork(ps_decode_op->u4_ts, work);
}
In order to render it, we need to know more about the YV12 format. It is a planar YUV variant with the following memory layout:

Pixel color information is stored in different planes Y for luminescence (basically giving black and white information), and U/V for chrominance (giving the actual color). Using a known colorspace matrix (such as BT.601 or BT.709), one can then compute the actual RGB pixel values from the YUV ones. This format very frequent for videos, has the advantage of using less memory for the same information (using some brain color perception shenanigan).
Indeed here with YV12, we store witdh * height for Y, and then half of that for U and V which equals in total to 2 * width * height instead of 3 * width * height for RGB.
So after getting the file with ADB we can render by letting ffmpeg do the work, with a little trick for the planes order. Indeed, ffplay doesn't handle natively YV12, however it is merely a planar variant so we use yuv420p and swap the planes to get the proper colors:
ffplay -x 1280 -y 720 -f rawvideo -pixel_format yuv420p -video_size 1280x720 -vf shuffleplanes=0:2:1 -i frame.yv12
So the frame after decoding is actually ok:

Next in line was the rendering of the frame, which works like this:
using eglCreateImageKHR (EGLClientBuffer is basically just a void * pointing to the AHardwareBuffer)GL_OES_EGL_image_external) extension (the shader is translated into NIR->TGSI)Similarly to the previous code after decoding, we can dump the frame right before it is bound to an OpenGL texture and still get proper colors.
The next step is the actual implementation of the eglCreateImageKHR call in mesa3d (which binds the native buffer to an EGL image), required a bit more work to dump the frames. Here we didn't have a high level Android graphical buffer with which we can lock with gralloc API. Instead we needed to know the actual buffer memory layout.
Thank you minigbm developers for this very useful comment:
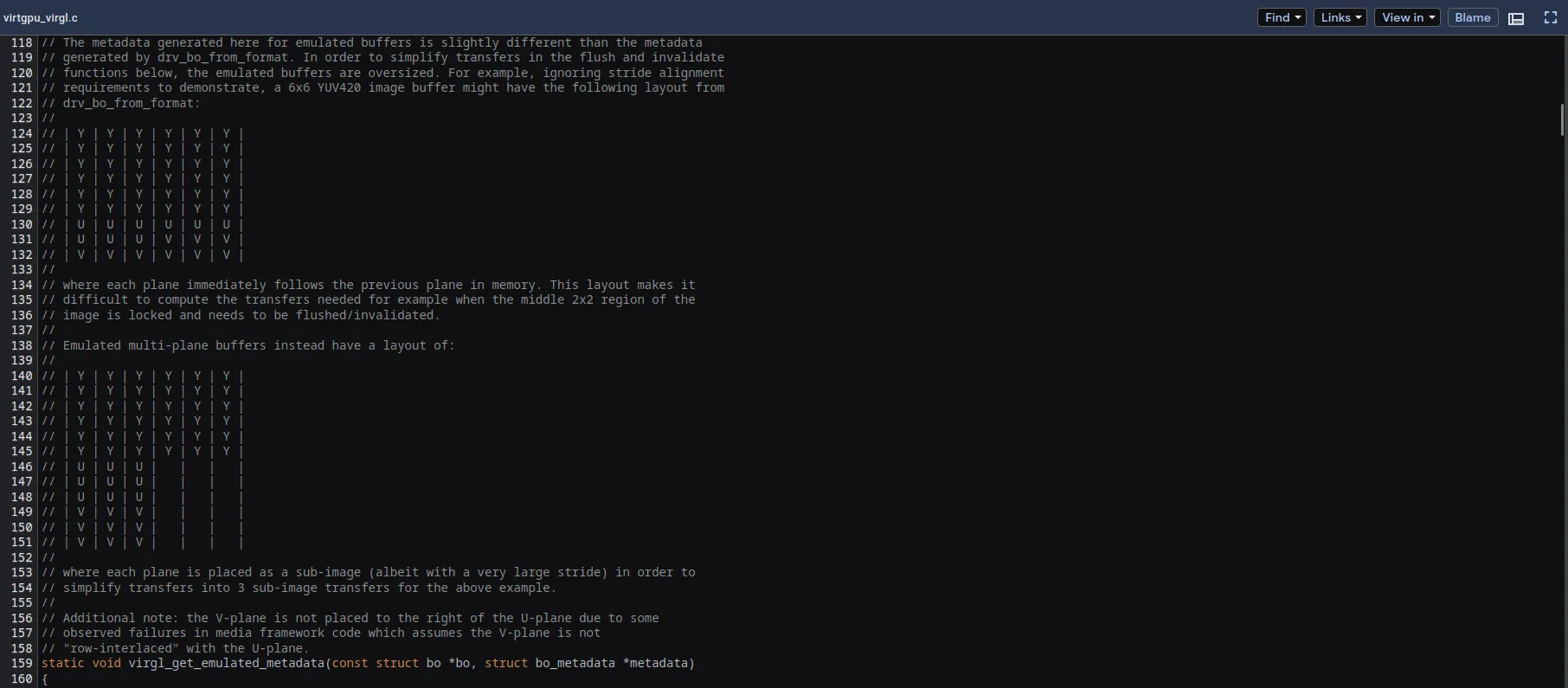
We also needed to know more about how the virtio-gpu is used for allocation. This DRM driver is enabled in the kernel with VIRTIO_GPU option and exposes DRM devices (/dev/drm/*) which allow to:
Finally in order to dump the frame, we had to use DRM ioctls to get file descriptors allowing to read the proper shared memory:
// Open the DRI device
int fd = open("/dev/dri/card0");
// Get a mapping of the planes in the global buffer object
struct drm_virtgpu_map gem_map = { 0 };
drmIoctl(fd, DRM_IOCTL_VIRTGPU_MAP, &gem_map);
// For each plane get a pointer the plane buffer
for (i = 0; i < num_planes; i++) {
void *plane_data = mmap(NULL, total_size, PROT_READ, MAP_SHARED, drm_fd, gem_map.offset);
}
After all this, the dumped frame was still properly displayed with ffplay !
The next logical step was to try and understand how Android was expecting the YUV frames to be rendered. As seen previously, the frame is declared as GL_OES_EGL_image_external and the shader (used by the Skia rendering engine), uses samplerExternalOES, which should actually handle the YUV to RGB conversion.
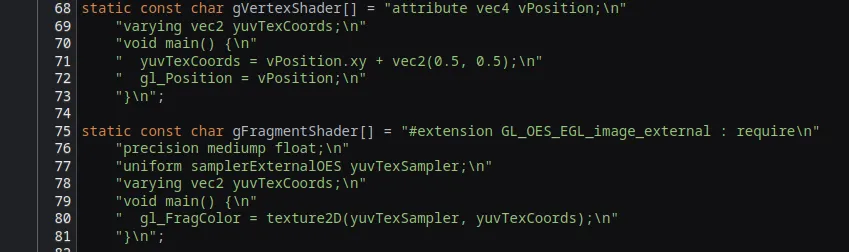
In order to simplify the problem we used a simple test OpenGL native program which was actually based on some existing Android native test.
It already uses the same kind of shaders for YUV color conversion:
We just modified it to load our previously dumped YV12 frame, and then render it using OpenGL:
// Allocate and lock the graphical buffer
yuvTexBuffer = new GraphicBuffer(yuvTexWidth, yuvTexHeight, yuvTexFormat, yuvTexUsage);
android_ycbcr ycbcr;
status_t err = yuvTexBuffer->lockYCbCr(GRALLOC_USAGE_SW_WRITE_OFTEN, &ycbcr);
if (err != 0) {
fprintf(stderr, "yuvTexBuffer->lock(...) failed: %d\n", err);
return false;
}
// Read the YV12 frame data
int fd = open("/data/local/tmp/frame", O_RDONLY);
if (fd < 0) {
printf("Failed to open file\n");
return false;
}
// Fill the buffer with the 3 planes data
int ysize = (yuvTexWidth * yuvTexHeight);
int csize = ysize / 4;
read(fd, ycbcr.y, ysize);
read(fd, ycbcr.cr, csize);
read(fd, ycbcr.cb, csize);
And with this, we get the same distorted and green/pink result as video players. Clearly the YUV to RGB conversion went bad somewhere.
We first tried replacing the use of samplerExternalOES with a sampler2D and do the actually conversion directly in the shader. We needed to declare 3 textures, one for each plane:
glTexImage2D(GL_TEXTURE_2D, 0, GL_LUMINANCE, width, height, 0, GL_LUMINANCE, GL_UNSIGNED_BYTE, ycbcr.y);
glTexImage2D(GL_TEXTURE_2D, 0, GL_LUMINANCE, width/2, height/2, 0, GL_LUMINANCE, GL_UNSIGNED_BYTE, ycbcr.cb);
glTexImage2D(GL_TEXTURE_2D, 0, GL_LUMINANCE, width/2, height/2, 0, GL_LUMINANCE, GL_UNSIGNED_BYTE, ycbcr.cr);
Then we shamelessly took some computation code from the chrome project and the frame was rendered properly. This proves our texture data is correct and all that remains is the conversion done in the shader.
The last step of our investigation was to try and debug the shader transfer from host to guest. This is initially handled by mesa, which converts glsl shaders to an internal format (tgsi) which gets converted back to glsl on the host by virglrenderer.
However, mesa introduced another intermediate language called NIR (which gets converted to tgsi if needed). In order to use that logic (and hope for maybe a fix somewhere in the more recent commits), we updated mesa to its latest tag 22.3 which uses NIR compilation of GLSL.
For anyone interested to build it in AOSP, this can easily be done using the meson build system by adding this to your BoardConfig-common.mk:
BOARD_MESA3D_USES_MESON_BUILD := true
BOARD_MESA3D_GALLIUM_DRIVERS := virgl
And this to your device.mk:
PRODUCT_SOONG_NAMESPACES += external/mesa3d/android
PRODUCT_PACKAGES += \
libEGL_mesa \
libGLESv1_CM_mesa \
libGLESv2_mesa \
libgallium_dri \
libglapi
When running our test program with the MESA_GLSL=dump environment variable, it will dump our glsl shader and its compiled version in NIR. However this didn't prove very useful because it the code still only referenced the usage of the samplerExternalOES.
Another possibility was to debug this in virglrenderer on the host because we know at some point it receives the TGSI shader (which is previously converted from NIR by mesa). Then virglrenderer will finally generate a glsl shader which can easily be dumped and looks like this:
smooth in vec4 vso_g9;
out vec4 fsout_c0;
out vec4 fsout_c1;
out vec4 fsout_c2;
out vec4 fsout_c3;
out vec4 fsout_c4;
out vec4 fsout_c5;
out vec4 fsout_c6;
out vec4 fsout_c7;
vec4 temp0;
vec4 temp1;
vec4 temp2;
uniform sampler2D fssamp0;
uniform sampler2D fssamp1;
uniform sampler2D fssamp2;
void main(void)
{
temp0.xy = vec2(((vso_g9.xyyy).xy));
temp1.x = float((texture(fssamp0, temp0 .xy).x));
temp2.x = float((texture(fssamp1, temp0 .xy).x));
temp1.y = float(( temp2.xxxx .y));
temp2.x = float((texture(fssamp2, temp0 .xy).x));
temp1.z = float(( temp2.xxxx .z));
temp1.xyz = vec3((( temp1.xyzx + -(vec4(0.0625,0.5,0.5,0.0625)))).xyz);
temp0.x = float(dot(vec3( temp1 ), vec3((vec4(1.164,0,1.596,0)))));
temp0.y = float(dot(vec3( temp1 ), vec3((vec4(1.164,-0.39199999,-0.81300002,0)))));
temp0.z = float(dot(vec3( temp1 ), vec3((vec4(1.164,2.017,0,0)))));
temp0.w = float(((vec4(0.0625,0.0625,0.0625,1)).w));
fsout_c0 = vec4(( temp0 ));
fsout_c1 = fsout_c0;
fsout_c2 = fsout_c0;
fsout_c3 = fsout_c0;
fsout_c4 = fsout_c0;
fsout_c5 = fsout_c0;
fsout_c6 = fsout_c0;
fsout_c7 = fsout_c0;
}
Here we can see recognize the BT.601 constants used for RBG conversion and see the three samplers (one for each plane as we did in our manual conversion previously).
After dumping the texture used in vrend_create_sampler_view using glGetTextureImage we notice that a single GL_R8 texture contains all three YV12 planes concatenated. The actual YUV values also seem wrong (the values are halved maybe because of a wrong computation somewhere).
Clearly mesa generates a shader for color conversion, but there should be at some point three separate textures, one for each plane, which can be bound by the three samplers. Now we know we need to look into how mesa and virglrenderer exchange the frame texture and shader to understand why the display isn't correct.
We're close but this is as far as we go for this first blog post !
We didn't need software video decoding that much, but this exercise is a great excuse to know more about the complex components which make up our graphic stack and get more insight on how everything is connected.
Hardware video decoding was added to the virgl protcocol, so we're excited to try the integration in AOSP ! Even though it won't fix YUV frame rendering in the general case, it will clearly avoid the issue in most cases. Most importantly, it will give us a big boost of performance, much need particularly when not using KVM.
One important piece of knowledge about how the virgl protocol works on our version: each texture upload from the guest is stored in guest memory and transferred to the host as well. This means higher memory consumption and also high CPU usage when uploading a texture often (typically ok for simple UI but not so great for rendering video). In order to use use a single shared buffer between host and guest, a feature called blob resource has been added in the virtio-gpu driver, and is being worked on in mesa, virglrenderer, crosvm and qemu. It is not yet officially usable in qemu, but some patches were sent to add such support (along with initial venus support). To use this we need to update mesa on the guest (any latest version will do, it's easy to integrate using the meson build), update the kernel (to at least 5.15 used for Android 13), use a recent virglrenderer (0.10.x), and apply some patches to qemu. We might also want to try venus at some point (vulkan support in mesa/virgl/qemu/virglrenderer); although considered experimental for now, it seems to be the way forward for future virgl use.




